 진행과정
진행과정
텍스트 분석 - 분석용 데이터셋 준비
1.
커뮤니티에서 소셜데이터를 추출

텍스트 분석 - 텍스트 데이터 확인 및 추출
1.
명사추출 - 제목과 내용을 이용
- 1차 명사 추출 후 17,009개 → 전처리 후 15,069개 → 최종 명사 추출 후 5,017개

텍스트 분석 - 자연어 처리
1.
Word2Vec - 단어의 의미를 반영하여 공간상의 벡터로 나타내는 기계학습 알고리즘으로, 단어 벡터 간 유사도 계산을 통해 특정 단어와 연관성이 높은 단어 도출
텍스트 분석 - 키워드 빈도 분석 및 시각화 분석
1. 제휴 업체 Q&A 분석을 위한 키워드 빈도 분석
2. 제휴 업체 Q&A 분석을 위한 워드 클라우드 시각화

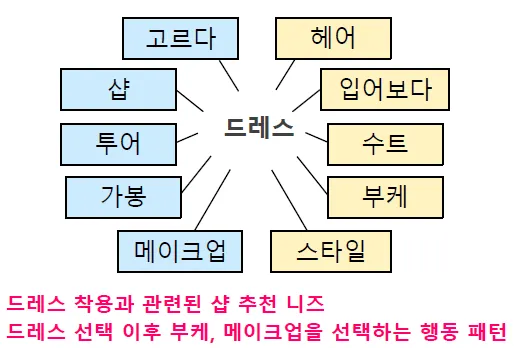
고객 니즈 파악에 대한 키워드 빈도 분석 예시
•
‘드레스’는 드레스 착용과 관련된 샵 추천에 관한 요구가 많았고 드레스 선택 이후 부케, 메이크업을 선택하는 행동 패턴을 보였다.
•
‘촬영’은 본식, 야외, 스튜디오로 세분화되는 경향을 살펴 볼 수 있었다.
•
‘홀’은 홀의 구조와 조명을 통해 연관 질문으로 이어졌으며, 연관 질문으로는 BGM, 드레스, 본식 스냅 등의 추천에 대한 요구가 있었다.

워드 클라우드 시각화 예시
•
최종 추출된 명사 5,017개 중 상위 20개의 빈도 그래프를 작성해보았다.
결혼, 추천, 웨딩 순으로 언급이 많이 된 것을 확인할 수 있고 드레스, 촬영, 홀, 예식, 결혼식, 스냅을 이용하여 Word2vec 분석에 활용하였다.
